SuiteTalk API
A product we’re developing integrates with an accounting platform. This platform is NetSuite, an industry leader, and provides a frighteningly comprehensive SOAP API called SuiteTalk. The API also contains SDKs for a number of languages, and while the documentation could be more extensive, generally it is a very stable and robust system to develop against.
The SuiteTalk API limits the number of concurrent requests on a per-account basis. By default, standard accounts are allowed a single concurrent request, with the option of upgrading to 10, then 20, and so on, depending on the throughput required by your application. So far, so good. What’s slightly awkward about this from a developer’s perspective though is that the restriction manifests as a SOAP error. This then requires your application to implement the connection pooling required to sensibly manage success and failure. In a distributed (and often ephemeral – in “the cloud”) environment with possibly disparate technologies, this isn’t a straightforward task.
As with all problems there are a number of possible solutions.
The easy way
The most basic solution to this problem, and the one that we initially went with, was as simple as just grinning and bearing it. The application is largely PHP based, so when we receive concurrency errors we simply toss the exception up the stack, either carrying on regardless or bailing out of the request/process.
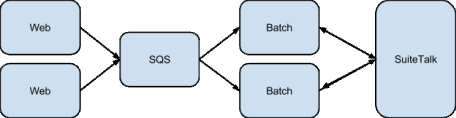
Now, this isn’t as bad a solution as it first appears. The system is architected so that the vast majority of communication with the SuiteTalk API is handled offline by batch processing servers; the web front-ends using SQS to offload these tasks. We ensure each task is idempotent, and in the face of error can be retried any number times. This has been an incredibly useful feature, allowing us to recover from all kinds of failures as the system has grown.
In the few cases where our requests to SuiteTalk originated from the front-ends the worst that could happen was sometimes a piece of the information presented to a user might be missing. This was deemed acceptable for launch, but as the user base grows it becomes too important an issue to ignore.
The hard way
To improve our situation the only options I could come up with involved either co-ordination or centralisation. Uh-oh…
The first possibility was that we could adjust our clients to co-ordinate via some service to manage access. This tactic wouldn’t have been ideal as we were using the SuiteTalk PHP Toolkit, meaning we’d need to either wrap all access to this, or infiltrate its internals to add our cross-network communication for access control. This kind of feature is notoriously difficult to implement correctly, especially without introducing some helper (like ZooKeeper) to manage it. Also, while we’re currently doing all SuiteTalk work with PHP, this might not always be the case.
The second solution, and the one I decided to try, was to add a proxy between our systems and SuiteTalk.
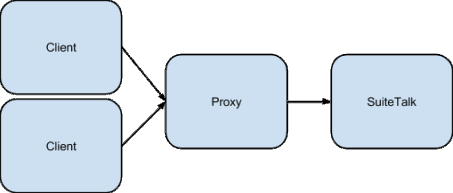
This would obviously add a single point of failure… but with a good amount of monitoring in place, and the application-side already being used to tolerating errors this was an acceptable risk.
Doing some research showed there are already a number of SOAP/HTTP proxies out there, but mainly in the ‘enterprise’ space (i.e. with a lot to install, manage, and possibly pay) and initially none I could find with the ability to limit the number of concurrent connections. Then I stumbled across an Apache module called mod_qos (Quality of Service), and at first this seemed very promising.
The Apache way
Apache needs no introduction, and while not being a ‘flavour of the month’ web server, it has stood the test of time. There is also a plethora of modules available, like this one. mod_qos provides lots of options to protect services using techniques like bandwidth restriction and limiting of concurrent connections; the latter sounding like just what I needed.
When the module is loaded, this directive allows you to restrict paths (from all sources) to the specified number of concurrent connections.
QS_LocRequestLimit / 1Unfortunately the mod_qos strategy for denying access when the concurrency rule is broken is not to block the client and wait for a free slot, but to throw a 500. This is basically mirroring the original problem, only with a quicker error, and it seemed I had exhausted my search for something off-the shelf.
The fun way
So, to roll our own; usually not the best solution of course when tried and tested alternatives already exist, but in this case it seemed like the fun way was my last best hope
I’ve written previously about how Clojure is my goto language for small services like this, and while thinking through the problem it struck me how some of the primitives in the new core.async library could be of use in controlling the concurrent access to the proxied resource (i.e. SuiteTalk). Here’s some pseudo-implementation:
(:require [clojure.core.async :refer [chan >!! take! alt!!]])
(defn make-handler [config]
(let [queue (chan (:max-connections config))]
(fn [req]
(handle-request chan req))))First, we create a fixed-size channel set to the number of concurrent connections we want to allow. By default a channel in core.async is just a queue like this:

A default channel
This channel will be available to all requests, and it’s the integration point we’ll use to control incoming requests.When a request arrives to the handler the first thing we do is put a message onto the queue using the blocking >!! operation.
(defn handle-request [chan req]
(>!! chan req)
(let [res (proxy-request req)]
(take! chan (constantly nil))
res))The effect of this will be that the first request arriving will find a channel with a free slot, so the put onto the channel will succeed instantly, and the request will move on to proxy-request where the request actually gets sent to the back-end server (SuiteTalk) and the response received.

A channel with a message on it
Now, while this is happening another request could arrive. Let’s say we only want to allow one concurrent connection, so our channel size will be one. This means that as the first request has already put a message into the channel, it’s full and there’s no more room. The result of this will be that when the second request gets to >!! it will block on the put, waiting until the first request is complete.

A channel with a message waiting, one that has been put, and another taken
Back to the first request… with proxy-request now returned we take! a message off the channel (asynchronously as we don’t really care about the result), freeing up a slot that any subsequent requests will be able to use to move on a step. So the >!! put for the second request will now succeed and it’ll proxy its request to SuiteTalk, and so on. If we want to allow more concurrent connections we simply increase the size of our channel. Neat!

Example of how a longer channel allows more concurrent connections
Now the above is just pseudo-implementation, and removes all the error handling and timeout handling from the real code, but it’s enough to get the idea of how it works.
Another neat trick from core.async is how we can handle timeouts when blocking with our initial put onto the channel. We want to block clients waiting to talk to NetSuite, but we can’t block forever and need to offer some sensible timeout. For this we use the alt!! macro, like this:
(defn offer [ch msg]
(alt!!
[[ch msg]] true
(timeout 30000) false)))This macro allows attempting multiple channel operations, returning the first one to succeed. So in the above code the nested vector syntax ([[ch msg]]) allows us to attempt a put onto the channel, and then (timeout 30000) creates a timeout channel that will return in 30 seconds. If the channel put gets called within the timeout period the message will make it onto the channel and this form will return true. Otherwise, the timeout will be used and false is returned. So it’s nice and simple to use this as a conditional put:
(if (offer ch msg)
(success)
(failure))Thanks to thegeez for this tip!
We’re not exactly using core.async for what it was primarily intended, no go blocks and CSP here, but the channel primitives are very useful.
So that’s the hard part of the solution out of the way. Everything around this is reasonably straightforward: a web-server to listen for requests; some functions for proxying to SuiteTalk; metrics; logging; and we’re pretty much done. It’s a small application, but even with bells and whistles everything fits quite neatly into its own namespace.
The tool is called Sweettalk and is available on Github if you’d like to check it out.
Conclusion
For us, this change means no more intermittent SuiteTalk errors. Our applications will always need to handle genuine failures, but having to harden the system to cope with this concurrency problem has almost been a blessing when we take into account the resilience it’s forced us to build in, and the lessons we’ve learnt.The one negative this change brings is that we now have a central point of failure for our communication with SuiteTalk. But we can look at adding failover as a further enhancement, and given that it’s such a simple solution, one that uses tech we’re already very familiar with monitoring and supporting in production, then the risk is very low.Another issue to note is that this method only works when all SuiteTalk calls go through this proxy. If we have other services tying up the connection pool then we’ll get those the same SoapFaults being returned here.No doubt there are plenty of other ways of handling HTTP concurrency; please let me know in the comments if you’ve encountered this kind of problem yourself and how you managed it if so.
At Box UK we have a strong team of bespoke software consultants with more than two decades of bespoke software development experience. If you’re interested in finding out more about how we can help you, contact us on +44 (0)20 7439 1900 or email info@boxuk.com.

