Increasing speed of releases
Over the last few years a movement seems to have emerged which is leading the development industry towards rethinking attitudes about how we release software, popularised by the Big Doggs like Facebook and Twitter. The old idea of planned releases staggered over months or years is being removed, with more and more people instead choosing to release not just early and often, but faster and faster while still holding on to quality. I think this change has been driven by the instant delivery nature of the web, and a proliferation of easily available and high quality tools and libraries.
Multiple considerations
But moving fast means having a workflow that helps, and doesn’t hurt. As a software company, at Box UK we are subject to a whole bunch of pressures which affect our demands for stability and flexibility in our codebases. These include…
- Clients needing a bug-free product to use.
- Developers needing a bug-free product to hack on (without wasting most of their time fixing bugs before getting anything done).
- Clients needing us to be able to release features quickly for their business goals.
- Developers needing to merge and release features quickly to save time and effort.
When planning our strategy for source control, and how we funnel changes from development to production servers, we need to support these, and any other demands, as best we can. After all, we’re lazy devs, and will do anything to avoid hard work!
Stable release model
When I joined Box UK, in times of yore, we’d just moved our core product from being versioned with Accurev to the (then) decidedly more hip Subversion. We standardised that, and our other products, on the mainstream model of having an unstable mainline trunk (to which we could commit code at any time), and periodically cutting release branches which would be tested, QA’d, etc… These release branches would then only usually receive bug fixes, and be the stable point which we could make release tags from.
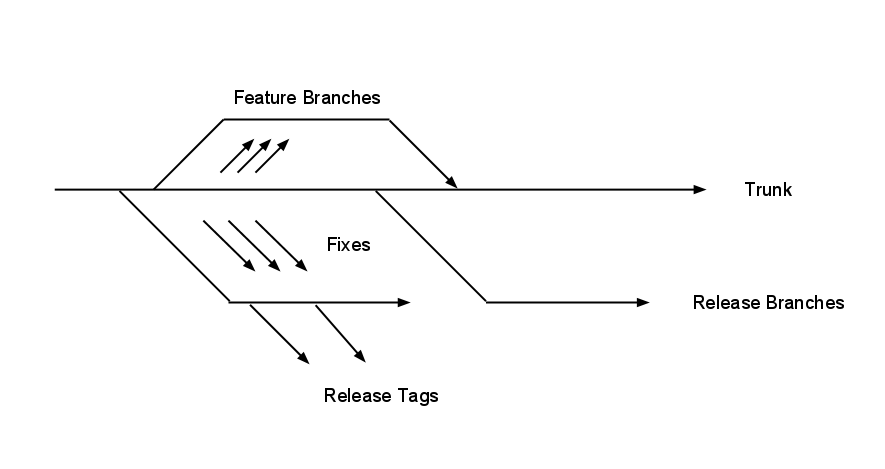
Stable release branch model
This (in my mind at least, feel free to disagree in the comments) is pretty much the standard model for managing the development and release of a software product, and has worked reasonably well for us since we adopted it.
Pros and Cons
When we’re working on new features our general workflow is:
- Cut a feature branch from trunk.
- As development progresses QA (Quality Assurance) gets involved.
- When complete, the feature branch is reintegrated with trunk, and then we either merge to the current release branch, or make a new one if it’s a big enough feature.
- Feature is released for client UAT (User Acceptance Testing) before final push to LIVE.
We also of course make smaller bug fix releases while the project cycle continues.
You’re probably already thinking about how your process differs or improves on this, but it’s a pretty well worn route and one I’d bet a large majority of software companies use (with different problems for different implementations!). As “reasonably well” as we find this works however, it’s not without its problems.
Issues with the model
1. Inaccurate testing / QA
The first issue that can occur is that the development and initial QA is done on a codebase that doesn’t actually reflect the state of what will ultimately make its way to the client for release. Whether you’re using Subversion, Git, or something else it doesn’t matter. The development code is two steps away from the live code.
2. Traffic jams
The next gotcha is that when multiple projects are going out at around the same time, after they’re merged to release, any delay in go live (additional requirements, change in client priorities, etc…) means they can block the path for other projects. We could merge stuff back out of release, but there could be more commits in there, and it’s basically not just a PITA but a problem that shouldn’t happen in the first place. Planning can help but this is always a potential headache. This problem is even more frustrating when you need to release quick support fixes.
3. Commit and run
Having an unstable trunk creates the temptation to commit code here when you’re not sure what to do with it. We assume it’ll get tested when the next release branch is made. But if it gets forgotten it could cause problems later.So, while we’ve been successfully using this model in all our projects for the last few years, it isn’t without its problems. Some can be minimised with discipline and toolage (note 1), but even then there are issues inherent in this model that can’t be totally removed. So can we do better?
Stable trunk model
As an experiment over the last few months we’ve moved some of our codebases onto a stable trunk model to see if it can help us. This model has the following general workflow:
- Trunk is stable, only good code goes here.
- Feature branches are cut from trunk, and only reintegrated when ready to go to LIVE.
- Release tags (note 2) are taken from trunk.
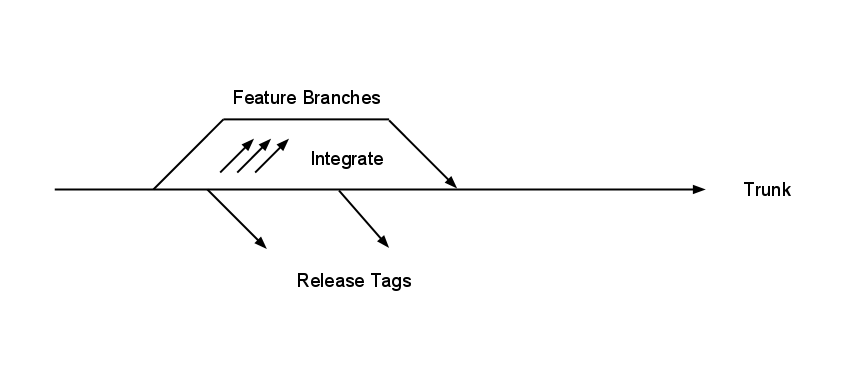
Stable trunk model
The general rule being if it’s in trunk it’s on LIVE. Using this model we can remove the three main problems that I mentioned earlier:
- Developers are now able to keep their feature branches up to date with trunk, and so be sure that what they’re developing and testing will be an exact copy of what will finally go live.
- Code is only merged to trunk when it’s absolutely ready to go live, this can be done literally seconds before release (possibly automated even). So now nothing can get into the release branch, stall, and back everything up behind it – there’s always a clear route to LIVE. Yay!
- Lastly, code can’t be dumped in trunk and forgotten because it’s going to straight to LIVE if anyone commits it here. So watch out! We’ve had to make sure this change is well known, as now anyone putting code in the wrong place could cause problems. Our tags still have version numbers of course, and these can now be completely focused on reflecting the level of change in the code.
Possible problems (and solutions)
As I said, we haven’t been using this model for very long, and only on a subset of our products. But one problem I can see that could possibly occur with larger codebases is merging fixes back to previous releases for clients that can’t just upgrade to latest. If this situation occurred we’d need to look at changing the tags we make from trunk to be more like branches that we could cherry pick fixes to – à la note 2.
Conclusion
This new model fits in well with the continuous delivery technique, and has been popularised by high profile companies like Github and Etsy. We’ve found it can be a more natural fit for the way we work, and it allows us to go faster. After successful trials we’re now rolling this out as the standard model for a large portion of our products; with active projects always on it’ll take a little time but we’re feeling confident that this is better for us.
Over the last year or two at Box UK we’ve also been making strides towards automating our development and release process, so the hope is in the future to hook this up with our CI (Continuous Integration) and possibly make more use of continuous deployment.
I’m sure people have created a gazillion ways of doing this, each with their own pros and cons. How do you manage code for release at your company, what problems have you faced, and what changes have you made to deal with this? Leave your own stories in the comments!
Links
http://zachholman.com/posts/how-github-works-asynchronous/http://codeascraft.etsy.com/2010/05/20/quantum-of-deployment/https://www.facebook.com/video/video.php?v=778890205865
Notes
- Toolage means, pertaining to tools. Is it just me that says this? I must have picked it up somewhere…
- Tags in this context could be more like branches so they can accept fixes.
At Box UK we have a strong team of bespoke software consultants with more than two decades of bespoke software development experience. If you’re interested in finding out more about how we can help you, contact us on +44 (0)20 7439 1900 or email info@boxuk.com.

